3. The Integrated Requirements Methodology
The methodology proposed here is an adaptation of the Kimball Lifecycle — the requirements-driven approach to data warehouse delivery developed by Ralph Kimball and Margy Ross over three decades of enterprise implementations — extended to incorporate AI feature design as a first-class concern alongside BI application design and dimensional modeling. The adaptation is based on a structural observation: the requirements for organizational AI features and the requirements for organizational data systems are not merely related — they are bidirectionally dependent.
Why Kimball?
The Kimball Lifecycle earned its place in enterprise data architecture for reasons that apply directly to AI governance. The methodology has been successfully utilized by thousands of data warehouse project teams across virtually every industry, application area, business function, and technical platform. Its endurance is not accidental — it solved the requirements problem that caused the 85% failure rate.
It starts with business requirements, not technology.
Kimball's methodology begins with stakeholder interviews — structured conversations with business users about how they think about their domain, what questions they need answered, and what processes they follow. This is precisely the missing step in AI governance: understanding how the organization works before encoding that knowledge into systems.
It organizes delivery by subject area, not by technology component.
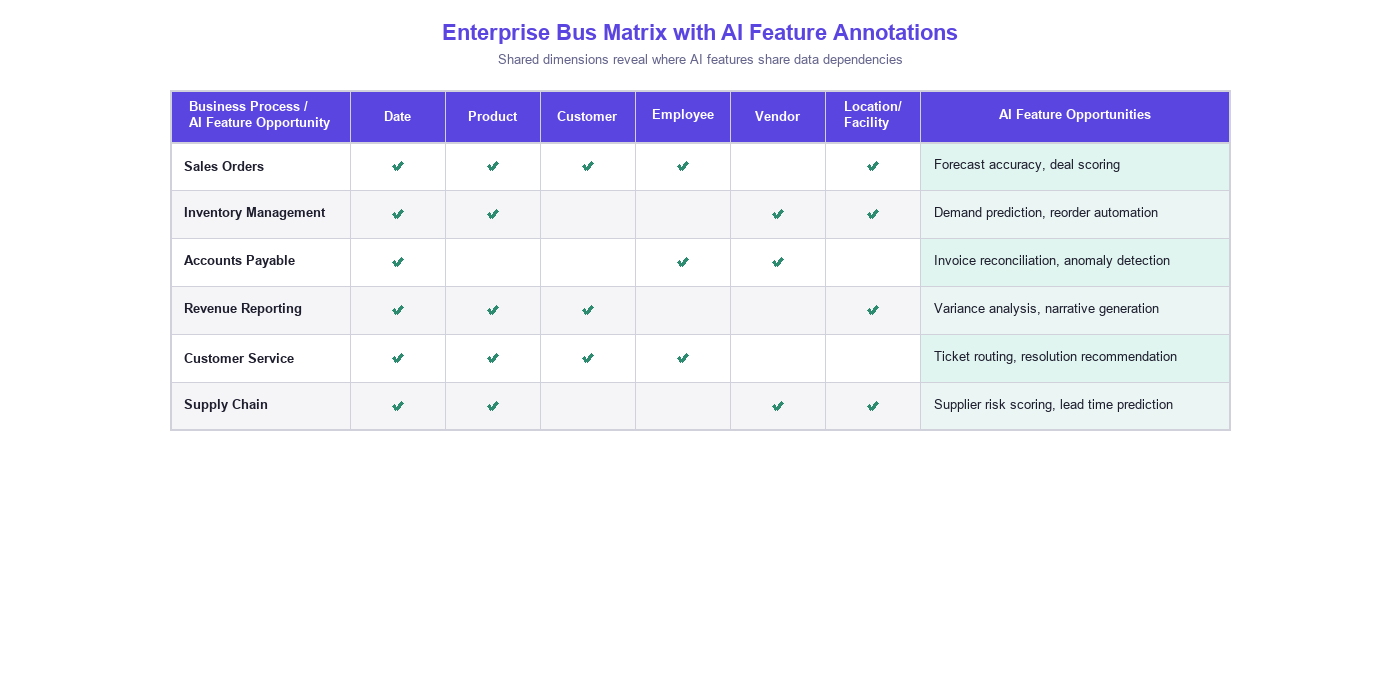
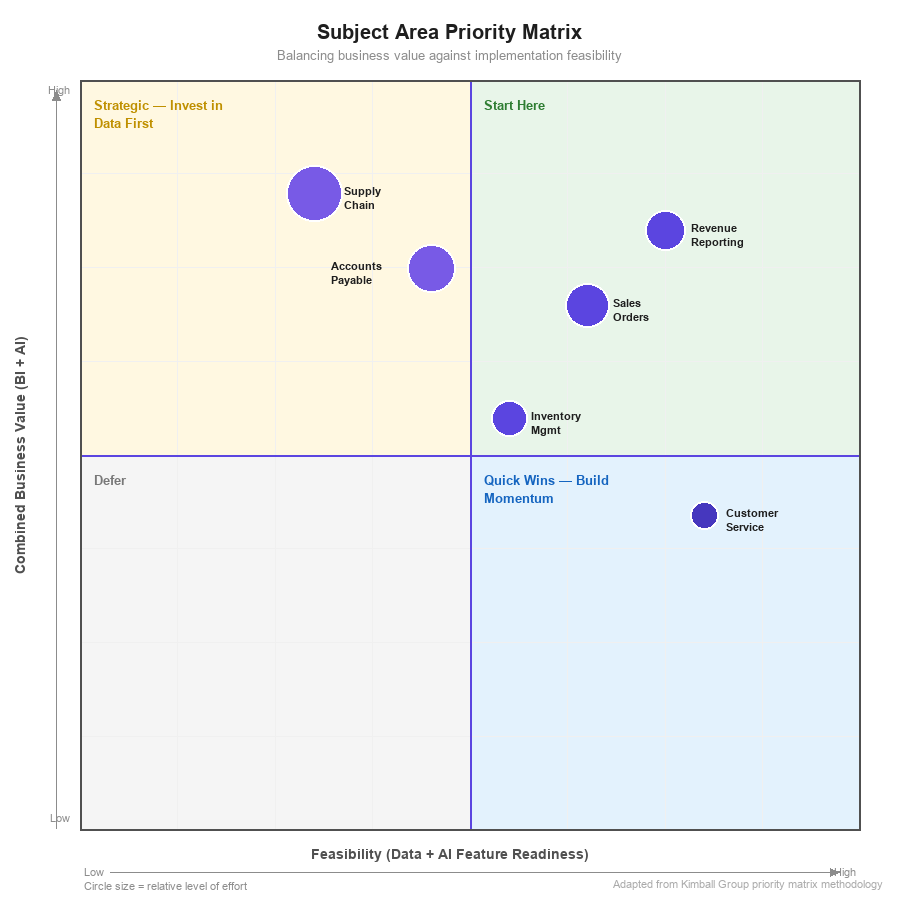
A Kimball data warehouse is built one business subject area at a time — Sales, then Inventory, then Finance — not one technology layer at a time. Each subject area delivers a complete vertical slice: dimensional models, ETL processes, and reporting. This incremental approach manages complexity, delivers early value, and maintains business alignment throughout the project.
It produces structured models of organizational knowledge.
Dimensional models are not databases — they are formal representations of how an organization thinks about its business. A well-designed dimensional model captures the grain of business processes, the hierarchies of organizational structure, and the measures that matter to decision makers. This is organizational knowledge encoded in a rigorous, maintainable format.
It addresses the #1 cause of project failure.
The Standish Group identified incomplete requirements as the single largest factor in IT project failure. The Kimball Lifecycle mandates structured requirements gathering as a prerequisite phase — directly addressing the root cause that kills most projects before they start.
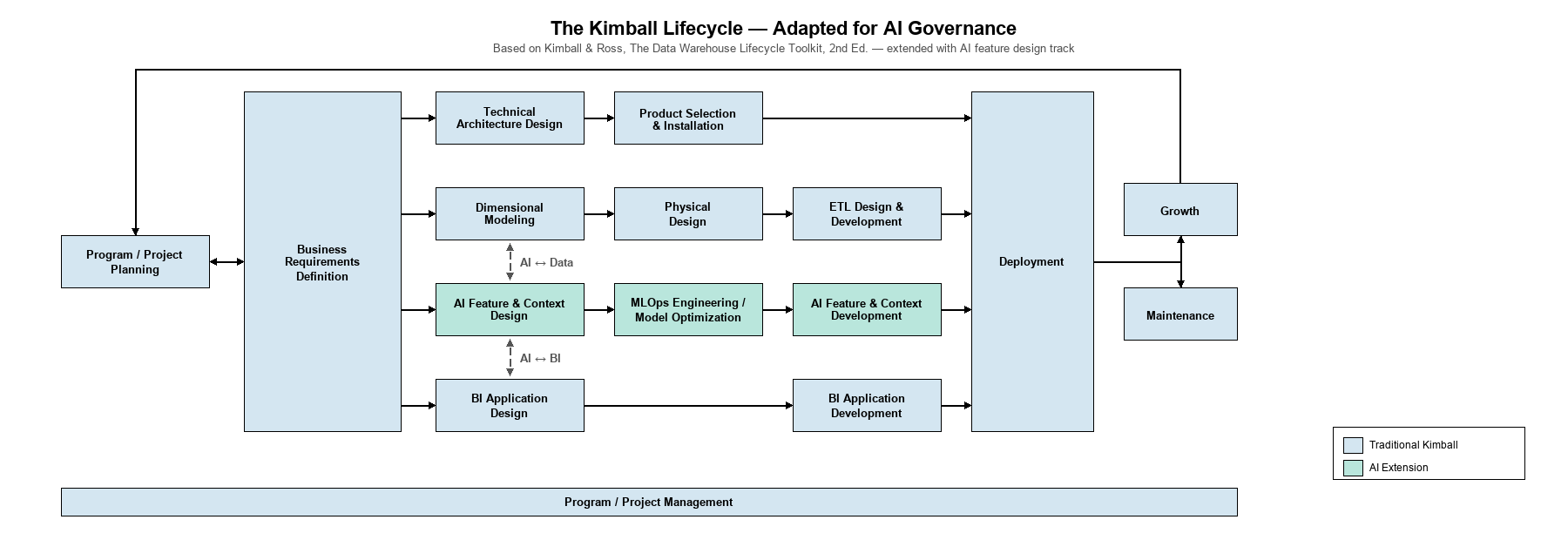
Figure 1: The Integrated Requirements Methodology — the Kimball Lifecycle adapted for AI governance, with an AI Feature Design track running alongside the BI Application and Data Foundation tracks.
The Adaptation: Bidirectional Requirements
The extension to AI feature design introduces a bidirectional dependency that traditional Kimball methodology does not address:
AI feature requirements drive data requirements. When stakeholders identify an AI capability they need (e.g., automated invoice reconciliation), that capability requires specific data to function. The AI requirement creates a data requirement.
Data availability shapes AI feature possibilities. When stakeholders describe their data landscape, the completeness and quality of that data determines which AI features are feasible. The data reality constrains the AI opportunity.
This bidirectional dependency is why separating data initiatives from AI initiatives fails. When run as separate projects, they discover gaps late: the AI team builds features that require data the data team has not prioritized, while the data team builds models that the AI team does not need. Dependencies surface during implementation rather than during requirements — the most expensive time to discover them.
The integrated methodology captures both sets of requirements simultaneously, in the same stakeholder interviews, producing a unified dependency graph that drives sequencing and prioritization.
What Separation Costs
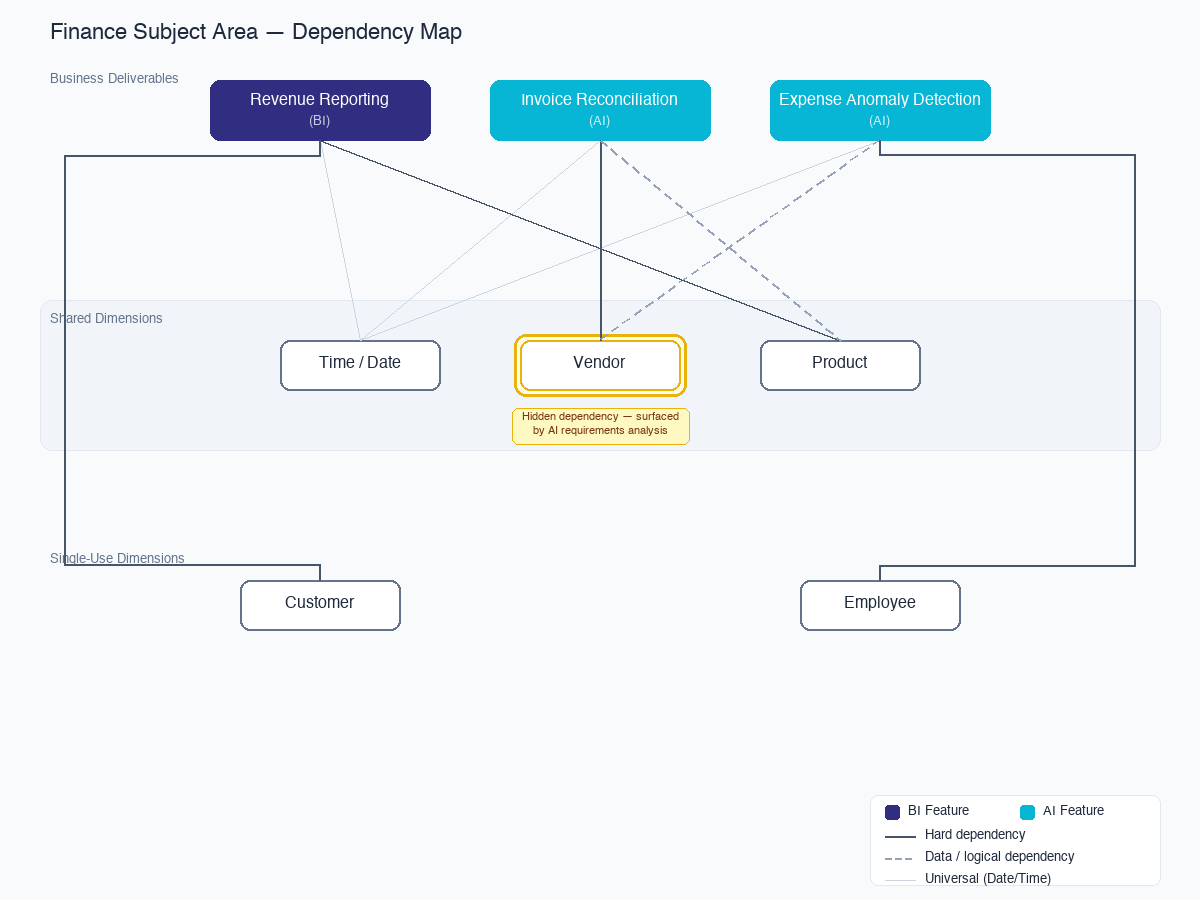
Consider a typical enterprise with a finance team that needs three things:
- Revenue reporting by product line (a data warehouse requirement)
- Automated invoice reconciliation (an AI feature requirement)
- Anomaly detection on expense reports (an AI feature requirement)
The invoice reconciliation feature requires clean vendor master data. If the data team does not know about the AI feature when they prioritize subject areas, they may deprioritize vendor data in favor of revenue data — after all, the revenue reports were requested first. Six months later, the AI team discovers they cannot build invoice reconciliation because the vendor data is not clean. They escalate. A new data project is initiated. Another six months pass.
In the integrated methodology, this dependency is captured in the requirements phase. The vendor data subject area is prioritized alongside — not after — the revenue subject area, because the dependency graph shows that two downstream deliverables depend on it.
This is not a theoretical risk. It is the default outcome when data and AI requirements are gathered separately.